


The Paths to Healthcare PLG (Part 2)
The Pathening (through LLM Unlock)

Special thanks to Brendan Keeler, Jay Rughani, Samir Unni, Matt Fisher, Aaron Maguregui, Alex Zhang, Dan Witte, Adam Steinle, Neha Katyal, Dave Bour, Paulius Mui, Blake Madden for feedback, inspiration, legal review, or general perspectives that led to this post. This was a particularly challenging post to write due to the legal complexity, so really grateful for all the help. None of the below is endorsed by anyone listed; simply my thoughts.
This is Part 2. Check out Part 1 here.
TL;DR
LLMs are uniquely good at redaction and can significantly de-risk these approaches from any potential PHI handling that might occur.
LLMs also can do redaction at small sizes, creating potential opportunities with client-side redaction.
There are many novel workflows to explore now that could be potentially viable for PLG. There are still other limitations and headwinds with going bottoms up, but redaction LLMs can provide compliance for real-time end user workflows.
It’s redundant, but to be explicit: patient privacy is paramount, and HIPAA despite its flaws requires compliance at the risk of fines, data breaches, loss of reputation, and loss of business. The goal here is not to evangelize circumventing HIPAA and parade around PHI willy-nilly, but rather to surface swim lanes where one can find more straightforward paths to providing lift to overlooked end users of healthcare.
And these end users need lift, yesterday, and a lot of it. So much so that the utilization of non-compliant shadow IT is growing by the day. The OCR may be sporadic in its investigation cadence (which likely leads to this growing utilization), but still the risk of audit & fine stands. The threat of data breach remains persistent all the same. Fines and breaches can dramatically impact large Covered Entities; they’ll level any software new entrant.
There have been clinician-facing tools that simply request user consent to exclude PHI in inputs (DocsGPT by Doximity, Glass Health) - while this seems to drive adoption for now, one can see the ceiling in this method.
Perhaps burdens get heavy enough to instigate relevant regulatory change, but until then: if you’re building products that has the potential to interface with PHI, even if you take any of the previously mentioned approaches, you run the risk of handling PHI and the subsequent potential consequences. So I guess it’s all for nought and you’ve read all this for nothing.
Not so. Enter…
The LLM Healthcare Unlock - PHI Redaction
De-identification Context
PHI redaction and de-identification of patient data are certainly not new concepts. To provide a quick recap, there are two methods:
Expert Determination: It’s in the name - an expert determines, using accepted statistical and scientific principles, that there is a very low risk that the information could be used to identify an individual, either alone or when combined with other available information. The expert must document the methods and analysis that support this determination.
Safe Harbor: If by removing 18 types of identifiers throughout the entirety of the data in question, and one cannot use the resulting information (or combine it with other information) to identify an individual, then the data is considered de-identified.
Important context around de-identification and HIPAA:
Only Covered Entities can “freely” de-identify PHI, and third parties that de-identify data on the behalf of Covered Entities must sign BAAs (as they must first willfully obtain PHI to de-identify it).
Re-identifying the data returns it to the protection of the Privacy Rule.
Putting de-identification into effect has high barriers to entry. An organization will require dedicated resourcing to deploy HIPAA-compliant, production grade redaction of their data. There’s often little reason to have this in-house. With breaches being costly (~$10M on average) and frequent, dedicating months to building (and more to maintenance) across data + engineering + compliance experts for something that isn’t revenue generative or a domain of expertise is a tough pill to swallow. If you turn to utilizing de-identification vendors, many offerings here are expensive and services-heavy, and turnarounds can range from days to weeks. It’s not unheard of for some vendors to go overboard in de-identification, rendering the data useless.
You could alternatively group patient profiles (aggregation) to de-identify and access aggregate-level insights and trends. This of course removes access to any individual-level granularity.
This has limited de-identification to use cases that make sense - commonly, de-identification via batch processing or patient profile aggregation enables macro-level research and insights for large provider organizations, policy makers, payers, pharma / CROs, life sciences and academia. AKA customers with large pockets whose data needs can tolerate slight delay. Building products for end users at Covered Entities (often smaller wallets), whose real time workflows need unimpeded, real time data flow for adoption to be viable, becomes essentially a no-go against the established path of building for enterprise and signing BAAs.
Meanwhile, end-to-end encryption can only enable safe data transfer; the entirety of the data is relatively useless for any additional processing while encrypted.
Now, back to everybody’s favorite new hype cycle, the LLM.
Democratization of Real-Time PHI Redaction
As you might know by now, LLMs are incredible at processing and analyzing inputs (text-based in particular) and converting said inputs into outputs of a desired format, in real time. This is directly applicable to de-identification with Safe Harbor - feed a properly trained LLM clinical data, and it can identify, redact, obfuscate PHI with incredible accuracy (definition below), while also enabling the remaining information to be processed unlike encryption.
To paint the picture: in a 2008 study, the poorest performing clinician annotator only achieved 63% accuracy; state-of-the-art models can achieve high 90s, with open source ClinicalBERT at 97.4% and OpenAI’s GPT-4 achieving over 99% off the shelf through strong prompting. If real world drift and bias can be monitored and accounted for, this seems to be production grade redaction at the ready. (Some additional thoughts by the ScienceIO team here).


One might observe that OpenAI’s BAA process has been reported to be challenging, and additional fine-tuning of open source models may be difficult in scope. Fortunately, there are already commercially available solutions, some of them even offering real-time APIs (Science.io’s Redact, Private AI, Gretel, potentially Mendel AI, more). Anthropic also recently announced HIPAA compliance and will sign BAAs.
This in and of itself isn’t groundbreaking; rather, it’s well known. However, it does have three implications.
As a reminder, while you’re handling PHI (including de-identifying it for further use), you are a business associate and require a BAA with your client. It’s inadvisable to go to market direct to clinician with willful neglect of HIPAA in hopes that the ephemeral presence of PHI prior to redaction is inconsequential. If audited, this will likely will not hold up in court, and it might get you banned by CISOs who deem the practice untrustworthy.
Real-time redaction does however remove risk for the product developer. If clinicians were to accidentally or deliberately input PHI without a BAA in place, with intentional messaging and safeguards, real-time redaction removes the business associate relationship and the potential of audit & fine. More importantly, the risk of actual breach is greatly mitigated.
For cloud-based tools that sit close to PHI workflows, this enables a more aggressive go-to-market.
If the redaction can occur on the Covered Entity’s servers / compute, subsequent information exchange can be compliant. Locally hosting ClinicalBERT requires not much more than 1 GB. A product that can leverage this while working with the limitations of hybrid or primarily on-prem architecture / local storage + compute can be downloaded and utilized by end users without violation of HIPAA. The barriers now lie on the prospect Covered Entity’s internal policies and utilization of endpoint management / access management systems or similar (Okta, Jamf, Windows Software Center, Citrix, Lookout, etc.). Though large health systems and payers will have stringent policies and systems, you could seek out smaller orgs with softer policies.
This might also unlock usage of some vendors who don’t yet offer BAAs or whose HIPAA-compliant tier is too costly. You will still likely want to obtain a BAA to CYA, or in the least be hyper-scrutinizing about how your de-identified data will be processed in the vendor of choice.
To summarize:
The Privacy Rule of HIPAA restricts exchange of data that contains PHI. Products & organizations that handle PHI must sign BAAs with Covered Entity clients.
If data with PHI is de-identified, the Privacy Rule no longer applies. Cloud service providers are no longer Business Associates and are safe from audits.
De-identification methods historically have been expensive and slow (often batch processing), and vary in accuracy.
LLMs enable highly accurate real-time redaction. Open source and commercial options are widely available today. Open source models can be locally installed for around 1 GB.
By increasing the universe of workflows that can meaningfully utilize PHI redaction, LLMs have increased the universe of products that can be securely deployed to end users at minimal risk to the product developer. The upper customer bound is with IT policies that restrict installation of local-hosted apps, which will be larger organizations - still, this is a new ceiling.
These points in sum, combined with the approaches from part 1, expose new possibilities for bottoms-up GTMs while staying compliant, compressing/circumventing BAA processes and maintaining patient privacy.
Reattribution

Nabla, one of the new entrant ambient clinical documentation companies (read more about this here), recently released this blog post regarding their approach to privacy and security. Particularly interesting to me was the detailed overview of their data flow. Nabla does the following:
Generates a transcript of conversation; this transcript is only stored locally (i.e. the physician’s computer)
Obfuscates PHI in transcript through pseudonymization; the pseudonym correspondence table is very temporarily stored.
Computing operations are performed on the redacted data to create a note
Re-attributes the note output with PHI through the temporarily stored pseudonym table; this output is only stored locally.
Deletes pseudonym table after each query.

Nabla’s data service is stateless, or at least almost so - save for the temporarily stored pseudonym correspondence table that is deleted upon each query, no inbound or outbound data is stored.
It seems to be the case that a couple organizations (Nabla, Athelas, many else) are utilizing this to go broadly direct-to-clinician (clinicians can utilize these products in live settings today on the free tier). I’m not yet perfectly convinced this is an infallible approach - as there are (brief) points in time where identifiers are processed and stored, this seems to operate in a gray area. It could be the case that moving redaction upstream to local servers would provide clearer compliance.
Bull case: the current approach drives fast adoption while avoiding breaches, leading to leverage and successful bottoms-up towards gaining market share. Bear case: I can see it draw scrutiny from CISOs with low risk tolerance, or competitors may file a complaint to the OCR.
I’ll be interested in seeing how the industry responds. To me, what this approach unlocks is preservation of context and output fidelity upon redaction.
However, assuming this approach can get buy-in, this further increases that universe of de-risked end user deployment. Real-time redaction (particularly on client side) de-risks workflows which have inputs with PHI. Real-time redaction combined with re-attribution + deletion also de-risks workflows which require PHI in outputs.
Utilizing this within one of the swim lanes from Part 1 creates intriguing PLG implications.
Which PHI-utilizing problem domains might now be viable for PLG?
We can break down this question with two factors: the input and the output of the workflow.
Do the inputs of the workflow often possess PHI?
Does the output of the workflow require PHI to sufficiently drive adoption?
In the previous era where de-identification via batch processing or aggregation were the only viable methods, the world of healthcare workflows looked like this.

In green are workflows that could be deployed to end users without signing BAAs up until recent. Below are examples.
Batch processing / data aggregation enabled workflows
Clinical trial design
Population health insights and analytics (ex. Komodo Health)
Academic research
Drug development
Market research
Model development
Real-time workflows that don’t require PHI in their input or output
The red colored nodes are restricted in adoption until BAAs are signed.
With the democratization of client-side real-time redaction by LLMs, the world of healthcare workflows starts to look like this.
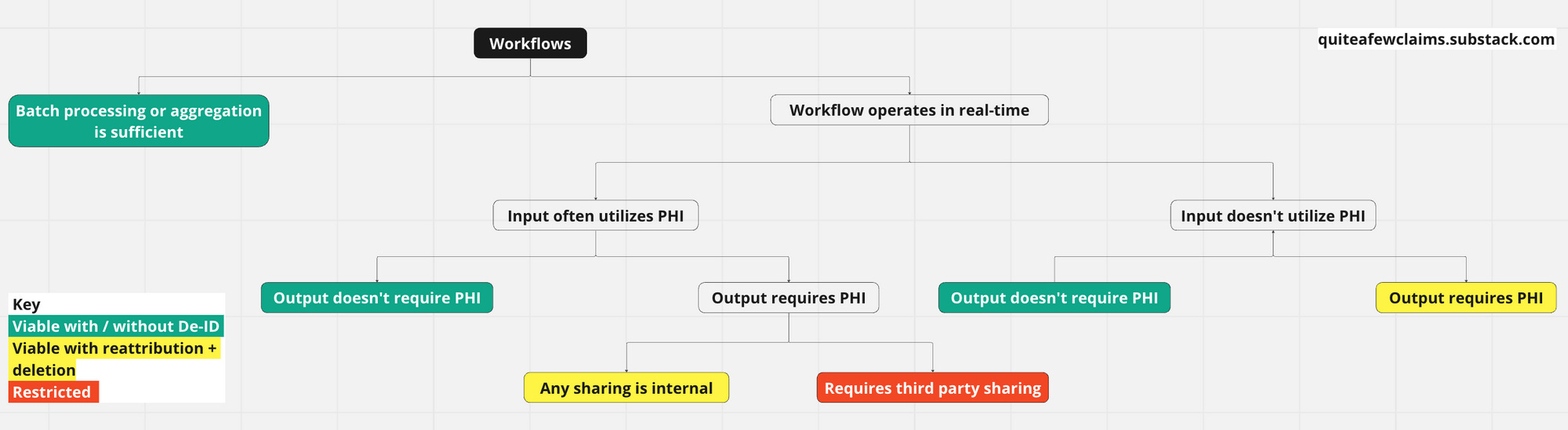
Newly green are real-time workflows that utilize PHI in inputs, but do not require PHI in output. Through real-time client-side redaction and perhaps some feature adjustments, products that are solving for these types of workflows could utilize a product-led, direct-to-end-user motion if relevant.
Some examples:
In-context information reference and analysis (ex. Atropos, Glass Health, AvoMD)
Care plan generation (ex. Glass Health, Oler Health)
Medication reconciliation
Advanced CDS / symptom checking / event monitoring (ex. Bayesian Health)
Non-PHI workflow triggering
With Nabla’s approach of de-identification + reattribution + deletion, combined with moving redaction to local servers, workflows internal to the Covered Entity that require PHI in outputs are viable as well. These are marked in yellow, and some examples below:
Info summarization (ex. Hona)
Coding attribution and audit (ex. Fathom, Nym Health)
Prior authorizations (ex. Develop Health, Latent Health)
Internal task management
Querying of patient information
The limitations here lie in the amount of compute that might need to be packaged with the client-side redaction app to ensure strong experience, and organizational policy and security systems. On HIPAA, it seems that this approach is compliant - please validate this with your legal advisor.
It’s critical to note that any workflows that require transaction of PHI with an external third-party will still run into HIPAA walls, and locally-installed applications will still need to be assessed by more stringent provider organizations.

What does this all mean?
In an industry marred with high costs, burnout, and poor experience, empowering the end user to be in the driver’s seat for product decisions might provide course correction. Furthermore, product-led growth motions can be a path forward for new entrants fighting uphill battles against incumbent organizations (more on these dynamics in my collaboration with Blake Madden and Paulius Mui).
If I had to guess, incumbents will likely continue to lean on their existing distribution networks - why wouldn’t they? To them, a product-led motion is unfamiliar and risky, and betting on ossification of user behavior and switching costs around their distributed products is a safer path. The added delta of cloud costs for redacting every query they process will be a tough pill to swallow as well.
Meanwhile, demand for improved workflows (for clinicians in particular) is increasing by the day. For instance, some physicians are paying for ambient documentation tools to the tune of $1500 per month out-of-pocket - producer surplus to be optimized.
To rehash some bits from my previous post - in creating defensibility against incumbents targeting your product vertical, you’ll probably want to target:
Strong UX focus and product execution - for AI products, this could look like AI-native, interlinked workflows such as downstream task triggering
Collaborative feature sets that create product network effects away from the legacy system
Not all workflows will be good fits. If the problem in question isn’t an end user (or end user team) problem, there’s less value in pursuing the motion. However, I think solutions for specific pain points can serve as excellent product-led wedges that can expand towards larger enterprise offerings. Finding overlooked problems that might have deeper product implications than they do on the surface can be key. With real-time redaction, one can strive beyond “product-led excitement” and gain enterprise leverage with actual utilization metrics.
There’s a ton of thread to be pulled at here. Some additional areas I’m curious about:
Can the current approach of organizations like Nabla and Athelas survive the long run, or are there alternative approaches that provide the same effect?
Where are the upper bounds for workflows that can be deployed client-side?
Having been primarily focused on provider clinical workflow recently, I’m curious what realms within payers, pharmacies, labs, etc. are enabled for PLG (and actually are appropriate for it).
With direct distribution to clinical end users being viable, is there any novel whitespace for patient-facing problems?
What are best practices to running PLG motions within healthcare?
One additional tangent - it’s interesting to imagine the possibilities for a “redaction rails” connector business. Such a business would sign BAAs with all relevant and willing CEs, and provide software vendors with de-identified data and deployment to customers while compressing cycles. I’d imagine a business like Redox (has done hard network building), Science.io (has CE customers utilizing Redact product) or Datavant (de-id network) could be well positioned here.
Thanks for reading, and I’d love to hear your thoughts on any and all of this considering all the fuzzy / gray areas it covers. Feel free to reach out in the comments or at my email | Twitter | LinkedIn.
"Nabla’s data service is stateless, or at least almost so - save for the temporarily stored pseudonym correspondence table that is deleted upon each query, no inbound or outbound data is stored."
This doesn't address the case where state does need to be stored, which we briefly discussed in the comments to the last post (https://quiteafewclaims.substack.com/p/the-paths-to-healthcare-plg-part/comment/18533170). It might be useful to add statelessness/statefulness to your workflow MECE. Without thinking too much about it, it seems like statefulness is necessary if:
1. Writing to source systems is challenging (e.g., the RPA doesn't work well enough for that).
2. The nature of your workflow is such that it produces data that doesn't fit into an existing system's data store.
If you need statefulness, you need somewhere to store that state. If you require both statefulness and are attempting true bottom-up adoption, then the place you store that state has to be decentralized (as discussed in the linked comments).